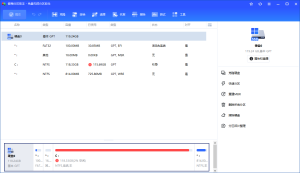
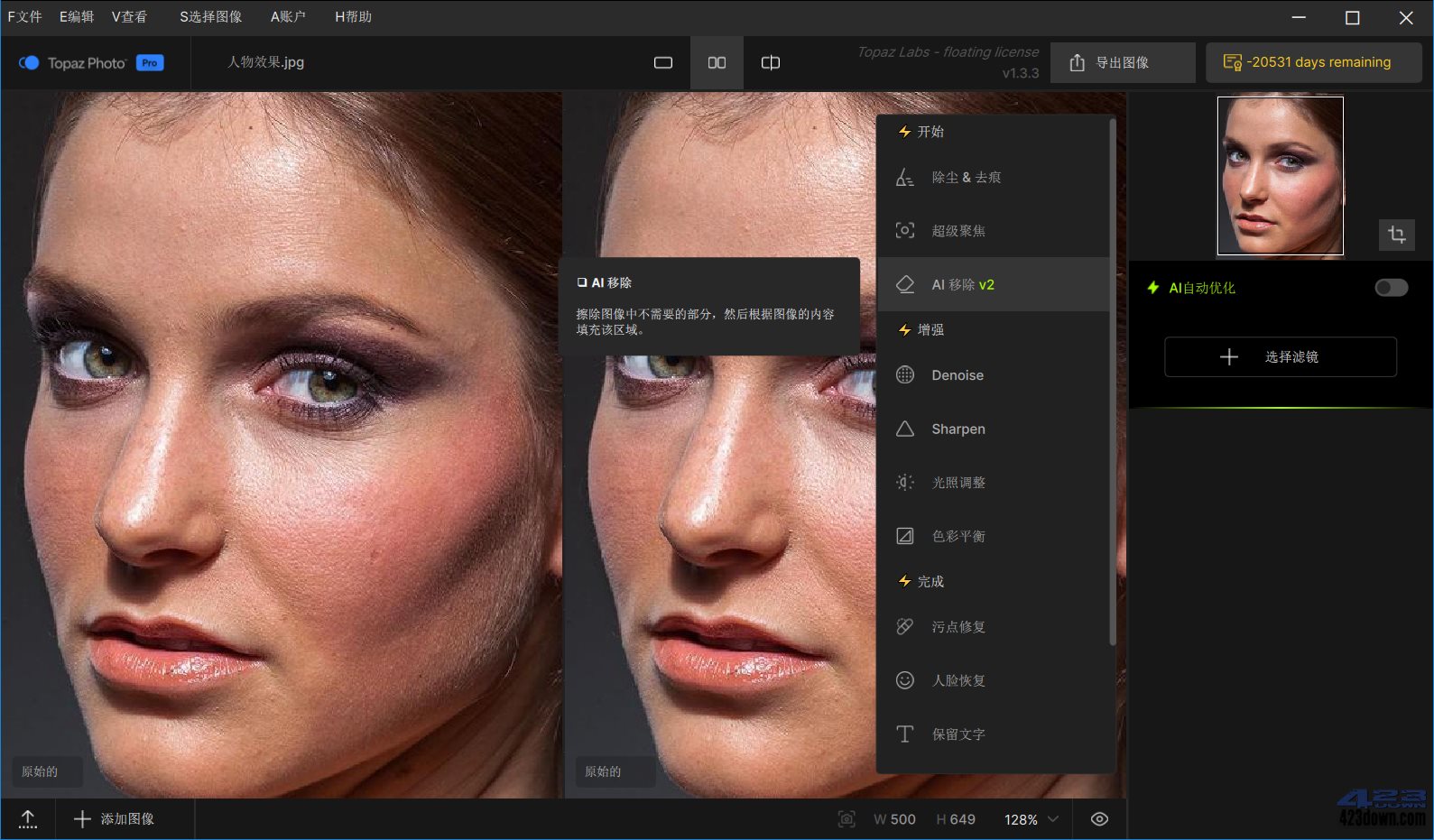
VIP解析搜索功能,也可以直接粘贴链接。

VIP接口已失效请更换 解析接口(百度一下,你就知道)
# -*- coding:utf-8 -*-
# file_name vip_video_final.py
__author__ = 'charon'
import tkinter as tk
import webbrowser
from tkinter import ttk
from tkinter.messagebox import showwarning
import requests
from bs4 import BeautifulSoup
txt_list = []
mapping = dict()
def center_window(window, w, h):
# 获取屏幕 宽、高
ws = window.winfo_screenwidth()
hs = window.winfo_screenheight()
# 计算 x, y 位置
x = (ws / 2) - (w / 2)
y = (hs / 2) - (h / 2)
window.geometry('%dx%d+%d+%d' % (w, h, x, y))
def do_search():
search_text = search_v.get().strip()
query_site = site_v.get().strip()
query = query_v.get().strip()
op_value = op_v.get().strip()
if op_value == 'link':
full_url = f'{query_site}?url={query}'
cbox.set(full_url)
print(f'full_url')
else:
print(f'query_site={query_site}, search_text={search_text}')
if search_text == '1':
fetch_teleplay_url(query, query_site)
elif search_text == '2':
fetch_movie_url(query, query_site)
else:
# 综艺
fetch_tv_show_url(query, query_site)
cbox['value'] = txt_list
if len(txt_list) > 0:
cbox.set(txt_list[0])
else:
showwarning('搜索结果', f'为找到{query}对应的电视剧,请尝试使用链接解析')
def play_video():
if op_v.get().strip() == 'link':
select_items = cbox.get()
webbrowser.open(select_items)
else:
select_items = cbox.get()
print(f'select_items={select_items}')
play_url = mapping[select_items]
webbrowser.open(play_url)
def fetch_teleplay_url(query, line=None):
global txt_list
if len(txt_list) > 0:
txt_list = []
mapping.clear()
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/103.0.0.0 Safari/537.36',
'referer': 'https://v.qq.com/'
}
url = f'https://v.qq.com/x/search/?q={query}'
html_content = requests.get(url, headers=headers, verify=False).content.decode('utf-8')
parser = BeautifulSoup(html_content, 'html.parser')
root_div = parser.find('div', attrs={'class': 'result_episode_list'})
if root_div is not None:
link_urls = root_div.find_all('a', attrs={'dt-eid': 'poster'})
expand_link = root_div.find('a', attrs={'dt-eid': 'expand_btn'})
movie_name = link_urls[0].get('dt-params').split('&')[0].split('=')[-1]
def handler_hide_url(ele_link):
v_id = None
site = None
page_num = None
detail = ele_link.get('dt-params')
for p in detail.split('&'):
if 'cid' in p:
v_id = p.split('=')[-1]
if 'site_id' in p:
site = p.split('=')[-1]
if 'pg_num' in p:
page_num = p.split('=')[-1]
cookies = {
'_pcmgr_localtk': '9QgVb6(74L',
'_qpsvr_localtk': 'O)6kvwidDd',
'pgv_info': 'ssid=s3912331901',
'pgv_pvid': '4948984288',
'tvfe_boss_uuid': '78adf163dd9d6537',
'video_platform': '2',
'video_guid': '991b6533a95a6b2b',
}
headers = {
'authority': 'pbaccess.video.qq.com',
'origin': 'https://v.qq.com',
'referer': 'https://v.qq.com/',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36',
}
params = {
'pageNum': page_num,
'id': v_id,
'dataType': '2',
'pageContext': 'need_async=true',
'scene': '2',
'platform': '2',
'appId': '10718',
'site': site,
'vappid': '34382579',
'vsecret': 'e496b057758aeb04b3a2d623c952a1c47e04ffb0a01e19cf',
}
detail_url = 'https://pbaccess.video.qq.com/trpc.videosearch.search_cgi.http/load_playsource_list_info'
res_json = requests.get(
detail_url,
params=params,
cookies=cookies,
headers=headers,
).json()
json_data = res_json['data']['normalList']['itemList'][0]['videoInfo']['firstBlockSites'][0][
'episodeInfoList']
return json_data
if expand_link is not None:
# 包含隐藏的部分
movie_detail = handler_hide_url(expand_link)
else:
movie_detail = []
for index, url in enumerate(link_urls):
movie_obj = {
'url': url.get('href'),
'title': index + 1
}
movie_detail.append(movie_obj)
for item in movie_detail:
play_url = item['url']
current_index = item['title']
full_url = f'{line}?url={play_url}'
title = '【' + movie_name + '】' + f'第{current_index}集'
mapping[title] = full_url
txt_list.append(title)
else:
print(f'没找到对应的电视剧')
def fetch_movie_url(query, line=None):
global txt_list
if len(txt_list) > 0:
txt_list = []
mapping.clear()
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',
'referer': 'https://v.qq.com/'
}
url = f'https://v.qq.com/x/search/?q={query}'
html_content = requests.get(url, headers=headers, verify=False).content.decode('utf-8')
parser = BeautifulSoup(html_content, 'html.parser')
root_div = parser.find('div', attrs={'class': 'result_btn_line'})
if root_div is not None:
link_item = root_div.find('a')
play_url = link_item.get('href')
detail = link_item.get('dt-params')
movie_name = detail.split('&')[0].split('=')[-1]
full_url = f'{line}?url={play_url}'
mapping[movie_name] = full_url
txt_list.append(movie_name)
else:
print(f'未找到{query}对应的电影')
def fetch_tv_show_url(query, line=None):
global txt_list
if len(txt_list) > 0:
txt_list = []
mapping.clear()
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/103.0.0.0 Safari/537.36',
'referer': 'https://v.qq.com/'
}
url = f'https://v.qq.com/x/search/?q={query}'
html_content = requests.get(url, headers=headers, verify=False).content.decode('utf-8')
parser = BeautifulSoup(html_content, 'html.parser')
root_div = parser.find('div', attrs={'class': 'result_link_list'})
movie_detail = []
if root_div is not None:
link_urls = root_div.find_all('a', attrs={'dt-eid': 'poster'})
expand_link = root_div.find('a', attrs={'dt-eid': 'expand_btn'})
# 先加载页面上已经存在的
for url in link_urls:
movie_obj = {
'url': url.get('href'),
'title': url.get('title')
}
movie_detail.append(movie_obj)
def handler_hide_url(ele_link, index):
v_id = None
site = None
detail = ele_link.get('dt-params')
for p in detail.split('&'):
if 'cid' in p:
v_id = p.split('=')[-1]
if 'site_id' in p:
site = p.split('=')[-1]
cookies = {
'tvfe_boss_uuid': '24c539ba5cc5db67',
'pgv_pvid': '4341653816',
'video_platform': '2',
'video_guid': 'f721a570554a868a',
'pgv_info': 'ssid=s8973242302',
'vversion_name': '8.2.95',
'video_omgid': 'f721a570554a868a',
}
headers = {
'authority': 'pbaccess.video.qq.com',
'origin': 'https://v.qq.com',
'referer': 'https://v.qq.com/',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
}
params = {
'pageNum': index,
'id': v_id,
'dataType': '2',
'pageContext': 'need_async=true&offset_begin=5',
'scene': '3',
'platform': '2',
'appId': '10718',
'site': site,
'vappid': '34382579',
'vsecret': 'e496b057758aeb04b3a2d623c952a1c47e04ffb0a01e19cf',
'g_tk': '',
'g_vstk': '',
'g_actk': '',
}
detail_url = 'https://pbaccess.video.qq.com/trpc.videosearch.search_cgi.http/load_playsource_list_info'
res_json = requests.get(
detail_url,
params=params,
cookies=cookies,
headers=headers,
).json()
json_data = res_json['data']['normalList']['itemList'][0]['videoInfo']['firstBlockSites'][0][
'episodeInfoList']
return json_data
if expand_link is not None:
load_all = False
current_index = 0
while not load_all:
# 包含隐藏的部分
result_data = handler_hide_url(expand_link, current_index)
current_index += 1
last_data = result_data[-1]
for movie in result_data:
if str(movie.get('displayType')) == '0':
movie_obj = {
'url': movie.get('url'),
'title': movie.get('title')
}
movie_detail.append(movie_obj)
if str(last_data.get('displayType')) == '0':
load_all = True
for item in movie_detail:
play_url = item['url']
title = item['title']
full_url = f'{line}?url={play_url}'
mapping[title] = full_url
txt_list.append(title)
else:
print(f'没找到对应的电视剧')
window = tk.Tk()
label3 = tk.Label(window, text="解析通道")
label3.grid(row=2)
##VIP接口已失效请更换 解析接口(百度一下,你就知道)
site = [('线路一', 'http://jx.webm.cc/?url='),
('线路二', 'https://jx.jsonplayer.com/player/'),
('线路三', 'https://yparse.jn1.cc/index.php')]
site_v = tk.StringVar()
site_radio_01 = tk.Radiobutton(window, text=site[0][0], variable=site_v, value=site[0][1])
site_radio_01.grid(row=2, column=1)
site_radio_01.select()
site_radio_02 = tk.Radiobutton(window, text=site[1][0], variable=site_v, value=site[1][1])
site_radio_02.grid(row=2, column=2)
site_radio_03 = tk.Radiobutton(window, text=site[2][0], variable=site_v, value=site[2][1])
site_radio_03.grid(row=2, column=3)
label3 = tk.Label(window, text="搜索类别")
label3.grid(row=3)
search_type = [('电视剧', '1'), ('电影', '2'), ('综艺', '3')]
search_v = tk.StringVar()
type_radio_01 = tk.Radiobutton(window, text=search_type[0][0], variable=search_v, value=search_type[0][1])
type_radio_01.grid(row=3, column=1)
type_radio_01.select()
type_radio_02 = tk.Radiobutton(window, text=search_type[1][0], variable=search_v, value=search_type[1][1])
type_radio_02.grid(row=3, column=2)
type_radio_03 = tk.Radiobutton(window, text=search_type[2][0], variable=search_v, value=search_type[2][1])
type_radio_03.grid(row=3, column=3)
label3 = tk.Label(window, text="搜索方式")
label3.grid(row=3)
op_type = [('搜索', 'search'), ('链接', 'link')]
label4 = tk.Label(window, text="搜索类型")
label4.grid(row=4)
op_v = tk.StringVar()
op_radio_01 = tk.Radiobutton(window, text=op_type[0][0], variable=op_v, value=op_type[0][1])
op_radio_01.grid(row=4, column=1)
op_radio_01.select()
op_radio_02 = tk.Radiobutton(window, text=op_type[1][0], variable=op_v, value=op_type[1][1])
op_radio_02.grid(row=4, column=2)
center_window(window, 520, 200)
window.title("vip视频解析")
window.resizable(0, 0)
query_label = tk.Label(window, text="视频名称")
query_label.grid(row=5)
query_v = tk.StringVar()
query_input = tk.Entry(window, textvariable=query_v)
query_input.grid(row=5, column=1)
search_btn = tk.Button(window, text='搜索', command=do_search)
search_btn.grid(row=7, column=2)
result_label = tk.Label(window, text="搜索结果")
result_label.grid(row=6)
cbox = ttk.Combobox(window,state='readonly')
cbox.grid(row=6, column=1)
play_btn = tk.Button(window, text='播放', command=play_video)
play_btn.grid(row=7, column=3)
window.mainloop()——- end ——-
不像复制代码可直接下载使用;
下载地址:
https://www.csev.cn/wp-content/uploads/2024/06/VIP视频解析.zip
https://wwi.lanzoup.com/i2fTT22ybxkd